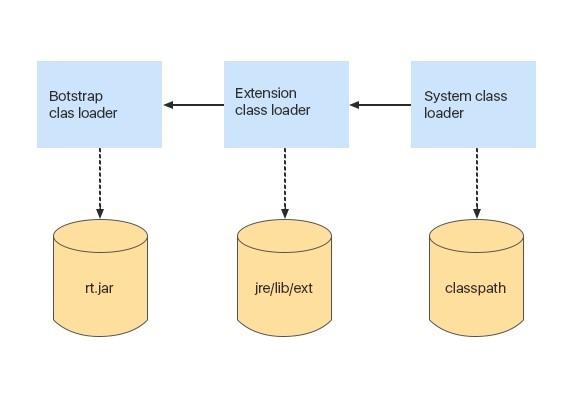
Bootstrap is a basic classloader that loads all system classes from rt.jar archive. At the same time, there is a slight difference between loading classes from rt.jar and our classes. When the JVM loads classes from rt.jar, it doesn’t perform all the verification stages, since the JVM is initially aware of the fact that classes from rt.jar are already verified. It means that you should not place any of your own files into that archive.
The next classloader is the Extension classloader. It loads Java extension classes from jre/lib/ext folder. Let’s say, you want a certain class to load every time JVM starts. In order to enable it, you can copy a source class file to that folder, and it will be loaded automatically.
Another classloader is the System classloader. It loads classes from the classpath we indicated when launching an application.
The process of classloading is performed by the following hierarchy:
- First of all, we request a cache search of the System Classloader that contains the classes that were previously loaded;
- If the class was not found in the System Classloader cache, we look for it in the cache of the Extension classloader;
- If the class was not found in the Extension classloader cache, we request it in the Bootstrap loader cache.
If the class was not found in the Bootstrap cache, Bootstrap tries to load this class. If the loading failed, the Bootstrap delegates loading to the Extension classloader. If the class is then loaded, it stays in the cache of the Extension classloader, and the class loading is complete.
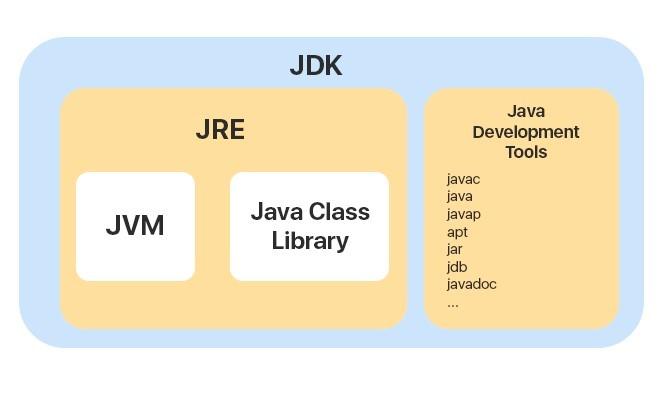
Java class structure. Loading of Java classes
Here we proceed directly to the structure of class files.
One class written on Java is compiled into one file with the .class extension. If our Java file has several classes, it can be compiled into several files with the .class extension respectively, namely into bytecode files of these classes.
All numbers, strings, class references, fields, and methods are stored in the Сonstant pool – the Meta space memory area. The class description is stored in the same area and contains a name, modificators, super-class, super-interfaces, fields, methods, and attributes. Attributes, in their turn, can contain any additional information.
Thus, when loading classes the following steps are performed:
- reading or verification of format correctness of a class-file;
- creating a class instance in the Constant pool area;
- loading of super-classes and super-interfaces; if they are not loaded, the class itself won’t be loaded either.
Bytecode execution on JVM
First of all, JVM can interpret a bytecode in order to execute it. Bytecode Interpretation is rather a slow process. During this process, an interpreter “runs” through the class-file line by line, and translates it into commands understandable by the JVM.
The JVM can also translate (or compile) a bytecode into a machine code, that will be directly executed on the computer’s processor.
Commands that are executed frequently, won’t be interpreted, they will be translated automatically.
Compilation
The Compiler is a programme that translates a source code from a high-level programming language to a machine code understandable for a computer.
Compilers are divided into:
- Non optimizing
- Simple optimizing compilers (e.g. Hotspot Client): works fast, but generates non-optimal code;
- Complex optimizing compilers (e.g. Hotspot Server): performs complex optimizing transformations before generating a bytecode.
Compilers can be also divided by the moment of compilation:
- Dynamic or Just-In-Time compilers
They work along with the program, thereby affecting its performance. It’s important for dynamic compilers to work on code that is executed frequently. During the program’s execution, JVM understands, which particular code is executed more often, and to avoid constant interpretation of this code, the virtual machine translates it into commands, that will be directly executed on the processor.
- Static compilers
While the compiling process is performed for a longer period, static compilers generate the optimized code for its execution. Static compilers do not need any resources during the execution of a program and each method is compiled using optimizations.
Java memory management
The Stack is a temporary memory space in Java. Stack memory is always referenced in LIFO order – “last in, first out”.
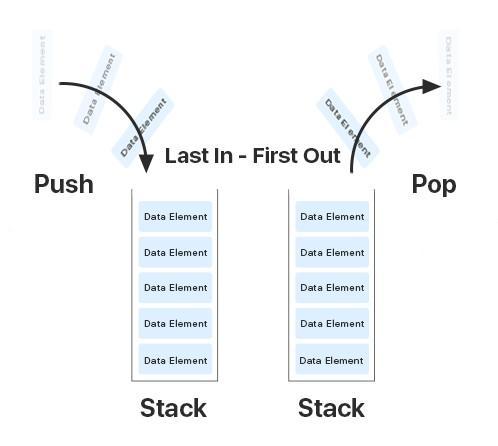
The Stack is needed to store methods. Variables in the stack are stored until the method they were created in will execute.
When a new method is invoked, a new frame of memory will be created on the top of the Stack. As soon as method ends, that block will be erased. The next method invoked will use that empty block. If the stack memory is full, Java will throw a xjava.lang.StackOverFlowError exception. For example, this can occur if there is a recursive function that invokes itself, and the Stack memory has overflowed.
Key Stack features:
- Stack is filled in and cleaned up as new methods are invoked and completed
- Access to this memory is considerably fast when compared to heap memory
- The size of the Stack is defined by the OS
- This memory is thread-safe as each thread operates in its own stack
Another memory space in Java is the Heap. It is used to store objects and classes. New objects are always created in the Heap, while references to these objects are stored in the Stack. Objects stored in the Heap are globally accessible, it means that they can be accessed throughout the application.
The Heap is divided into several parts called generations:
- Young generation is a field, where recently created objects are stored;
- Old (tenured) generation is a field, where long-life objects are stored;
- Before Java 8, there was one more memory space – Permanent generation. it contained meta-information about classes, methods, statistical variables. After Java 8 was invented, all this information then became stored separately in the Metaspace.
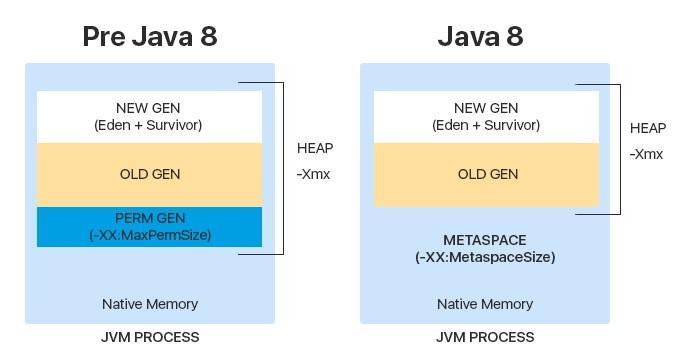
Why was the decision taken to get rid of Permanent generation? First of all, it was because of the error connected with memory overflow. Since the Perm had a constant size and could not expand dynamically, sooner or later the memory ran out, an error was thrown and application crashed.
In contrast, Metaspace has a dynamic size, and during its execution, it can expand up to the memory size of the JVM.
Key Heap features:
- If Heap space is full, Java throws java.lang.OutOfMemoryError
- Access to the Heap is relatively slower in comparison to the Stack
- To remove unused objects from the memory in the Heap, a Garbage collector is used
- Unlike stack, a heap isn’t thread-safe and needs to be guarded by properly synchronizing the code
Based on the information above, let’s take a look at the process of memory management with a simple example:
public class App {
public static void main(String[] args) {
int id = 23;
String pName = "Jon";
Person p = null;
p = new Person(id, pName);
}
}
class Person {
int pid;
String name;
// constructors, getters/setters
}
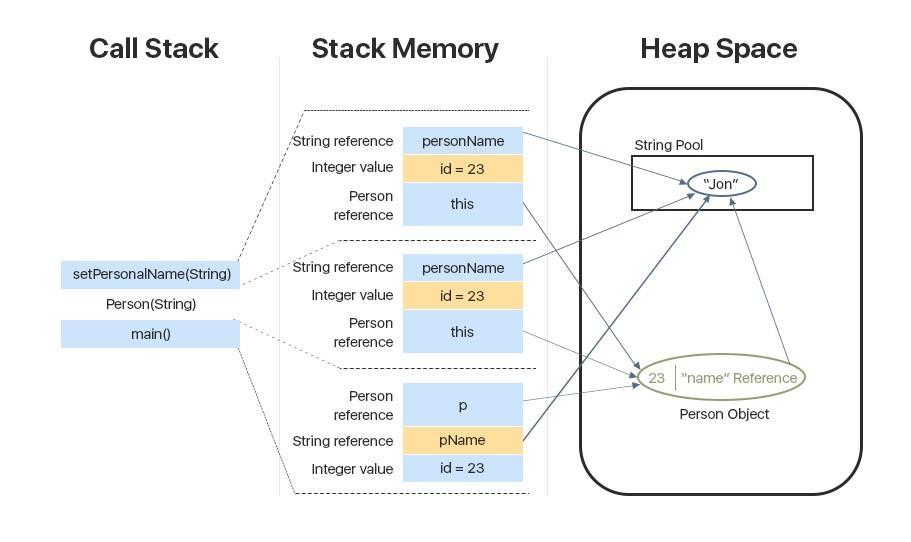
Now, let’s analyze this step by step:
- Upon entering the main() method, a space in stack memory would be created to store primitives and references of this method:
-
- The primitive value of the integer id will be stored directly in the stack memory
- The reference variable p of the type Person will also be created in the stack memory, which will point to the actual object in the heap
2. The call to the parameterized constructor Person(int, String) from main() will allocate further memory on top of the previous stack. This will store:
-
- This object reference of the calling object in stack memory
- The primitive value id in the stack memory
- The reference variable of String argument personName which will point to the actual string from the string pool in the heap memory
3. This default constructor is further calling setPersonName() method, for which further allocation will take place in stack memory on top of the previous one. This will again store variables in the manner described above.
4. However, for the newly created object p of type Person, all instance variables will be stored in the heap memory
This allocation is explained in the following diagram:
Garbage collection in Java
Garbage collector is a programme that works in JVM and is intended to delete objects that are no longer used or needed.
Different JVMs can have different algorithms of garbage collection, so there are a variety of different garbage collectors in Java.
Right now, we will talk about the simplest garbage collector – Serial GC. In order to request a garbage collecting process, we use the System.gc() command.

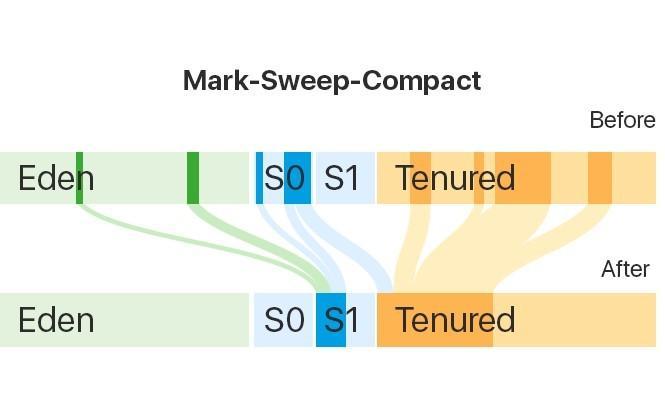
As already mentioned, the Heap memory is divided into 2 sections called Generations: New generation and Old generation.
New generation includes 3 regions: Eden, Survivor 0, and Survivor 1.
Old generation includes the Tenured region.
So what happens when we create a new object in Java?
First of all this object goes to the Eden. If we have created a lot of objects and there is no more memory for new objects, the garbage collector is triggered and frees up memory: it cleans up the Eden region and relocates all surviving objects to the Survivor 0 region. Thus, the Eden is completely cleaned.
If the Eden was filled with new objects again, the garbage collector begins to work with both Eden region and Survivor 0 region. After the collection, the surviving objects will go to another region — Survivor 1, while the two other regions will remain empty.
During the following garbage collection, the Survivor 0 region will be chosen as a target region again.This is why it’s important that with one of the regions – Survivor 0 or Survivor 1 – is always empty.